Pedagogy
25 Teaching and Learning with Archival Materials through the Development of Interactive Computational Notebooks
Philip Piety, Mark Conrad, Richard Marciano, Isaiah Cornfield, Elissa Boland, Rosemarie Fettig, Eden Hansen, Henry Kemp, Tahura Turabi
This chapter introduces a novel method that allows students and faculty to collaborate through digital treatments of archival and primary source materials using interactive, cloud-based, digital computational notebooks. We demonstrate this approach using North Carolina City Directories from the DigitalNC Collection (https://www.digitalnc.org/collections/city-directories/), a collection which is mirrored at the Internet Archive and publicly available. City and business directories from the nineteenth and twentieth centuries contain the names and addresses of residents, businesses, and telephone subscribers in thousands of cities across the US, and are a valuable record of local activities and demographics. The 1911 Historical City Directory of the city of Charlotte, NC, was used in a 15-week graduate course focused on implementing digital curation through hands-on, experiential learning.
Our chapter explores curriculum development and assessment using interactive, open-source Jupyter Notebooks: “A notebook is a shareable document that combines computer code, plain language descriptions, data, rich visualizations like 3D models, charts, graphs and figures, and interactive controls. A notebook, along with an editor (like JupyterLab), provides a fast interactive environment for prototyping and explaining code, exploring and visualizing data, and sharing ideas with others.”[1]
The purpose of this approach is to train the next generation of students and professionals to work in an increasingly digital and computational landscape and to enable faculty to teach courses needed to prepare future practitioners to manage digital collections. Our goal is to modernize archival and library education and contribute to the development of faculty and library “digital leaders.”
Importance/Challenges of Learning Computational Skills
The vast majority of records that will be acquired by archives moving forward are being created in digital form. Digitization of existing analog archival holdings is an ongoing and expanding activity for most repositories. Computational technologies for managing, describing, accessing, compiling, mining, and reusing digital content are advancing exponentially.
As Federal agencies such as the National Archives and Records Administration (NARA) are planning an even greater all-digital records future,[2] there is a critical need to strengthen digital and computational literacy and training for future librarians, archivists, and practitioners. Recognizing acute skills and management gaps in libraries, the Institute of Museum and Library Services (IMLS) highlighted the need for greater automation in library work, the facilitation of computational research, and the need for library managers to understand the benefits of in-house data science skills.
IMLS also funded a number of initiatives to enhance the training and professional development of the library and archival workforce to meet the digital needs of their communities:
- [2018-20] CT-LASER project developed a framework for mapping Computational Thinking (CT) to Library and Archival Science Education & Research. See: https://ai-collaboratory.net/wp-content/uploads/2020/11/Final_Report_r.pdf.
- [2020-23] Piloting Network aimed at prototyping a pilot to support MLIS training through a collaborative network of educators and practitioners that enables the sharing and dissemination of Lesson Plans and CASE Projects. See: https://ai-collaboratory.net/projects/piloting-network/.
- [2022-25] TALENT Network (Training of Archival & Library Educators w. iNnovative Technologies) takes our Piloting Network to the next level by scaling and accelerating its adoption and deployment. See: https://ai-collaboratory.net/projects/talent-network/.
In the last few years, fueled by COVID-19 restrictions and advances in digital scholarship, cultural institutions such as GLAMs (Galleries, Libraries, Archives & Museums) have provided new forms of access[3] to the public through collections presented as data using the Jupyter Notebook platform, however, few of these notebooks are currently adapted for LIS audiences or the public.
Background
This innovative approach for developing computational skills with future archivists comes from work that began in 2016 and has been known as Computational Archival Science (CAS), which combines principles of Computational Thinking and archival science as discussed below. [4]
Computational Archival Science (CAS)
CAS is an emerging, interdisciplinary field that blends traditional archival practices with computational tools. In pioneering CAS work, the computational notebook emerged as a popular tool that was easily shareable and made data and computational processes amenable to review, evaluation, comment, and instruction.
Computational Thinking (CT)
Computational Thinking as a concept can be traced to Wing’s seminal 2006 paper, where she proposed that it should be a fundamental skill used by everyone in the world by the middle of the 21st Century. This has led to a period of developing scholarship with multiple models for learning in K-12 settings.[5] For this line of work, the four-part model advanced by Weintrop was used to structure activities and as an analytic lens. Definitions of 22 CT Practices are shown in Table 1.[6] We also demonstrate the remapping of these CT concepts to archival science concepts.[7]
| Category | Description |
|---|---|
| Data Practices: |
|
| Modeling & Simulation: |
|
| Computational Problem Solving: |
|
| Systems Thinking Practices: |
|
Computational Archival Science Education System Website (CASES)
Initial work in CAS led to the realization that new kinds of instructional resources would be valuable for this community. The Computational Archival Science Education System (CASES) is a publicly accessible repository for computational notebooks and curricular material. The original conception was that this would be available for both instructors and students, and would include datasets, exemplar computational notebooks, and lesson plans. This site (https://cases.umd.edu) is organized around particular primary source-based inquiries, including titles known as “The Legacy of Slavery: Revealing Untold Stories,” “Redlining in Baltimore: Racialized Zoning,” “Japanese American WWII: Biographical Framework Of Citizen Incarceration” and others. While developed in archival science communities, these instructional resources may have value to a broad range of educators.
Case Study of Computational Notebooks Used in Graduate Education
While these culturally-based digital source documents and computational resources appear to have applicability to a range of instructional settings,[8] a study at a large public university on the East Coast involving graduate students in a course on digital curation provided an opportunity to study how students would respond to these opportunities using project-based learning.[9] In the spring of 2023, the course had ten students who were exposed to computational notebooks and computational thinking. Student learning was scaffolded[10] by the instructor. All ten students had successful projects and were able to use the resources provided with a number of digital tools. All demonstrated some elements of Computational Thinking. The ways they approached this opportunity and their learning products varied.
Dealing with Scale
Scale in digitized cultural heritage collections should no longer come as a surprise. The city of Charlotte (North Carolina) 1911 Historical City Directory book, as scanned and OCR-ed by the Internet Archive, yields close to 2GB of data (Charlotte itself comprises a time series of 62 Directories spanning an 89-year period). Directories for the entire state of North Carolina cover over 100 cities, spanning over a 100-year period (from 1860 to 1969), with close to 1,000 directories in aggregate. This represents up to 2TB (Terabytes) of digital content for the state of North Carolina alone. A rough extrapolation to the entire United States potentially leads to 100TB of data (or two hundred 500GB hard-drives).

We illustrate data-science-driven approaches to unlocking archives by accessing collections on the Internet Archive, and moving the 1911 Historical City Directory pages of Charlotte, North Carolina through two processing pipelines: 1. datafication (the first three assignments as shown in Figure 3), and 2. data analysis (the last three assignments shown in Figure 3):

- For datafication, students are asked to go inside and steer what are too often considered “black box” processes including: 1. OCR (Optical Character Recognition) management using ABBYYFineReader for experimentation of image to unstructured text, 2. cleaning and transforming unstructured to structured text (i.e., data wrangling) using OpenRefine and Trifacta tools, and 3. text processing (Natural Language Processing / Named Entity Recognition text tagging) using GATE/ANNIE).
- For data analysis, the resulting enhanced structured text is ready to be: 4. represented spatially through the creation of maps (using QGIS geographical information system tool), 5. visualized interactively through the creation of analytics dashboards (using Tableau data analytics tool), and 6. modeled through social networks (using Neo4j graph database). While Artificial Intelligence (AI) and Machine Learning (ML) are not explicitly featured, they are also discussed in Assignments 2 and 3.
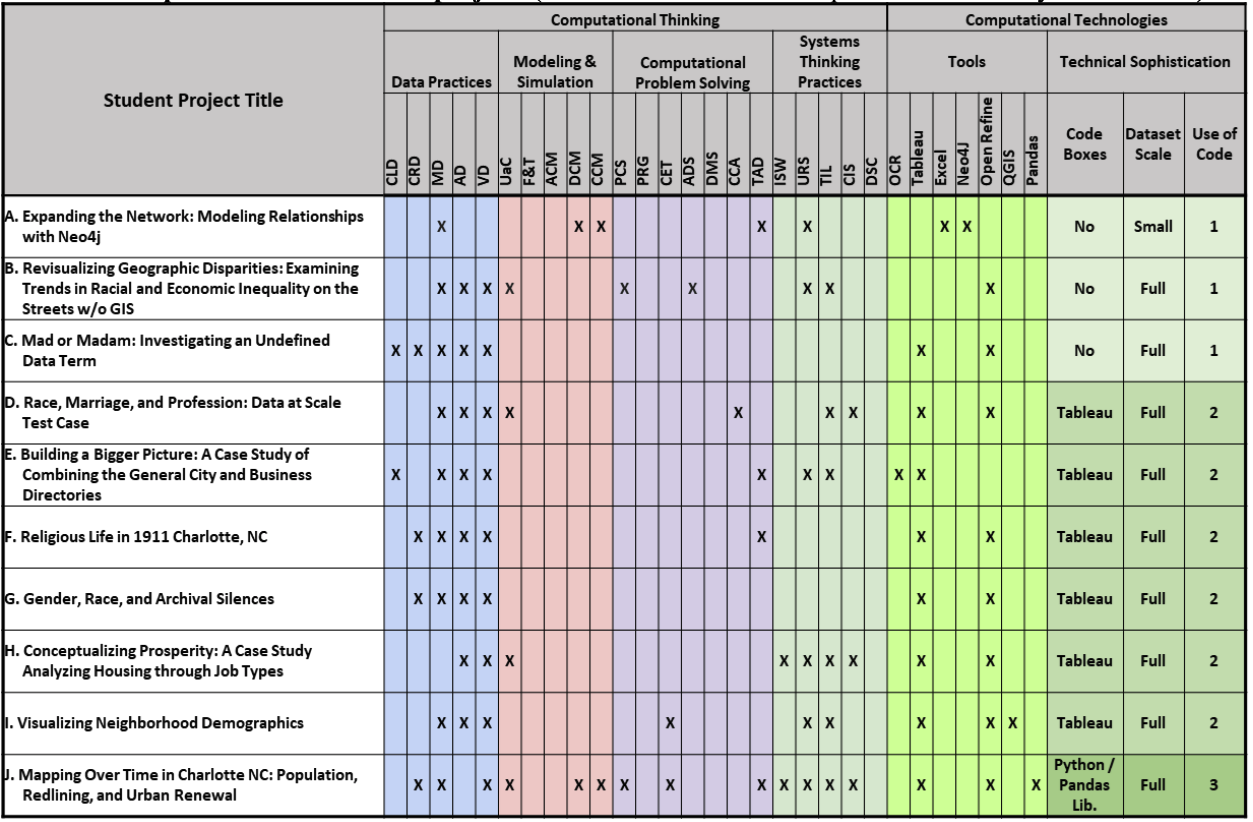
Variation in Student Decisions with Project-Based Learning
The pedagogical approach was one where each student was given the freedom to choose a data-based question analyzing the Charlotte 1911 collection and selecting a mix of technologies to answer it. Students applied the competencies developed earlier in the course. This variation, as shown in Table 2, illustrates how these kinds of instructional resources may be used differentially by different students. The affordances of this kind of resource can support students with different interests and skill levels in the same class. See the videos and notebooks at: https://ai-collaboratory.net/2023/05/11/may-11-2023-computational-storytelling-datathon/.
In-Course Evaluation
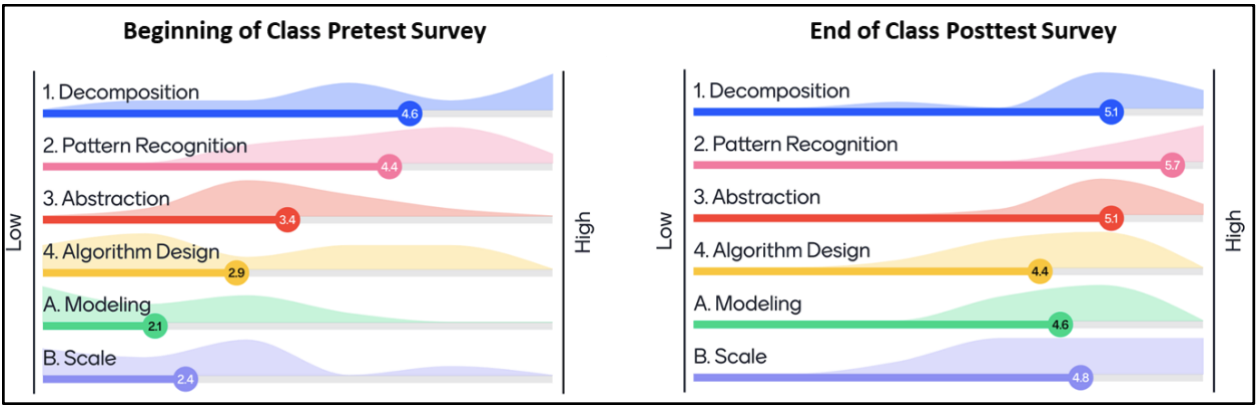
The course used in-course evaluations, including an instructor-developed, anonymous survey using the Likert scale and administered at the beginning and end of the class. The results of this survey (n=10) indicate students perceiving growth in their understanding of all categories with the greatest growth in their understanding of abstraction, algorithmic design, modeling, and scale. These categories were drawn from Wing’s 2006 foundational paper and preceded the introduction of Weintrop’s model for the class. This survey and Weintrop’s model served both pedagogical and analytic purposes and the students were not research subjects but collaborators as indicated by many of them being co-authors.
Students provided feedback through a number of mechanisms. In addition to the survey, students provided formal class evaluations, informal class feedback, and post-class evaluations. A summary of comments follows:
Students had a positive experience in the course, which provided practical experience and developed their computational thinking skills. They appreciated the ability to learn asynchronously through videos and the freedom to choose their final project question. The course was fast-paced due to their limited background in digital sciences, but the step-by-step instruction videos were helpful. Students suggest the inclusion of more applicable examples and broader application of concepts. They value collaboration and open sharing in the field of digital curation and believe future archives coursework should continue to emphasize this. The hands-on experience complemented their theory-focused coursework and increased their confidence in exploring new technologies. Integrating certain tools with Jupyter Notebooks presented challenges, but students recognize the value of using notebooks for documentation and sharing workflows. They mention a culture clash between traditional MLIS students and this teaching method, calling for bridging the disciplinary boundary. Students also note the lack of instructors with coding and computer science backgrounds in MLIS programs but remain optimistic about the increasing number of individuals with such skills in the evolving field.
Implications for Instructional Innovation
As with most instructional materials, including source documents, different instructors may use them in different ways. What this project illustrates is how the blend of computational thinking approaches and technologies with cultural datasets has led to student engagement, substantive student project artifacts, and (we argue) preparation for future learning. This combination has led to more than meaningful participation and evidence of learning. It has also provided students with an activity that has authentic social significance: reparations for the abuses of slavery and systemic racial oppression. Each student was able to engage with this multilayered social situation inscribed into land use policies and ownership in a specific way. No two projects are alike and yet they are all coherent around this theme, as professional work does not replicate itself for each professional but forms a composite.
Looking past graduate education in the library and archival fields, there are many possibilities in undergraduate and secondary education. Any teaching setting where source documents might be used would be suitable for this approach. Any course teaching computational skills where some students find a didactic and theory-focused approach less engaging might benefit from the techniques this pilot project deonstrated. Instructors will want to consider the extent to which traditional presentation approaches and testing regimes relate to this kind of approach.
Acknowledgments
We wish to acknowledge the support of two current Laura Bush 21st Century Librarian (LB21) grants: 1. “Piloting an Online Collaborative Network for Integrating CT into Library and Archival Education and Practice” (RE-246334-OLS-20), and 2. “Launching the TALENT Network to Promote the Training of Archival & Library Educators with iNnovative Technologies” (RE-252287-OLS-22). These grants are advancing data science education and infrastructure across the library, archives, and museum ecosystems.
This work benefited immeasurably from the contributions of Dr. Michael J. Kurtz, who was an inspiring mentor, collaborator, and dear friend of many in this research community. Dr. Kurtz was grounded in the core principles of archives and their social value as well as being a visionary who saw the potential of computational technology in this cultural work.
Endnotes
[1] “Project Jupyter Documentation — Jupyter Documentation 4.1.1 Alpha Documentation.” n.d. Jupyter.org. Accessed September 29, 2023. https://docs.jupyter.org/en/latest/, archived July 22, 2024, at https://web.archive.org/web/20240722202053/https://docs.jupyter.org/en/latest/
[2] The OMB/NARA Memo, M-23-07, dated December 23, 2022 states that no later than June 30, 2024, all permanent records in Federal agencies will have to be managed electronically for eventual transfer and accessioning by NARA: https://www.whitehouse.gov/wp-content/uploads/2022/12/M_23_07-M-Memo-Electronic-Records_final.pdf, archived July 17, 2024, at https://web.archive.org/web/20240717212547/https://www.whitehouse.gov/wp-content/uploads/2022/12/M_23_07-M-Memo-Electronic-Records_final.pdf
[3] See for example: Awesome Jupyter GLAM, https://github.com/LibraryCarpentry/awesome-jupyter-glam, “A curated list of awesome Jupyter notebook projects and guides in the GLAM (Galleries, Libraries, Archives, and Museums) community,” archived July 24, 2024, at https://web.archive.org/web/20240723150814/https://github.com/favicon.ico
[4] Richard Marciano, Victoria Lemieux, Mark Hedges, Maria Esteva, William Underwood, Michael Kurtz, and Mark Conrad, Archival Records and Training in the Age of Big Data, in J. Percell, L.C. Sarin, P.T. Jaeger, J.C. Bertot (Eds.), Re-Envisioning the MLS: Perspectives on the Future of Library and Information Science Education, (Advances in Librarianship, Volume 44B, pp.179-199). Emerald Publishing Limited (2018), https://ai-collaboratory.net/wp-content/uploads/2020/10/Marciano-et-al-Archival-Records-and-Training-in-the-Age-of-Big-Data-final.pdf, archived July 24, 2024, at https://web.archive.org/web/20240724151748/https://ai-collaboratory.net/wp-content/uploads/2020/10/Marciano-et-al-Archival-Records-and-Training-in-the-Age-of-Big-Data-final.pdf.
[5] Shuchi Grover and Roy Pea, “Computational Thinking in K–12: A Review of the State of the Field,” Educational Researcher 42, no. 1 (2013): 38–43, https://doi.org/10.3102/0013189×12463051.
[6] David Weintrop et al., “Defining Computational Thinking for Mathematics and Science Classrooms,” Journal of Science Education and Technology 25, no. 1 (2016): 127–47, https://doi.org/10.1007/s10956-015-9581-5, archived February 11, 2024, at https://web.archive.org/web/20240211011041/https://link.springer.com/article/10.1007/s10956-015-9581-5.
[7] Richard Marciano et al., “Reframing Digital Curation Practices through a Computational Thinking Framework,” in 2019 IEEE International Conference on Big Data (Big Data), IEEE, 2019, https://ai-collaboratory.net/wp-content/uploads/2020/04/ReframingDC-UsingCT_final.pdf. See: Section II, archived January 10, 2024, at https://web.archive.org/web/20240110193416/https://ai-collaboratory.net/wp-content/uploads/2020/04/ReframingDC-UsingCT_final.pdf.
[8] Rajesh Kumar Gnanasekaran and Richard Marciano, “Piloting Data Science Learning Platforms through the Development of Cloud-Based Interactive Digital Computational Notebooks,” in Proceedings of International Symposium on Grids & Clouds 2021 — PoS(ISGC2021 Trieste, Italy: Sissa Medialab), https://ai-collaboratory.net/wp-content/uploads/2021/10/ISGC2021_Gnanasekaran_Marciano.pdf, archived July 24, 2024, at https://web.archive.org/web/20221219212456/https://ai-collaboratory.net/wp-content/uploads/2021/10/ISGC2021_Gnanasekaran_Marciano.pdf.
[9] Phyllis C. Blumenfeld, Elliot Soloway, Ronald W. Marx, Joseph S. Krajcik, Mark Guzdial, and Annemarie Palincsar, “Motivating Project-Based Learning: Sustaining the Doing, Supporting the Learning,”Educational Psychologist”, 26, no. 3–4 (1991): 369–98, https://doi.org/10.1080/00461520.1991.9653139.
[10] Annemarie Sullivan Palincsar, “The Role of Dialogue in Providing Scaffolded Instruction,”Educational Psychologist, 21, no. 1–2 (1986): 73–98, https://doi.org/10.1080/00461520.1986.9653025.
Media Attributions
- Private: p1
- Private: p2
- Private: p3
- Private: p4
- Private: p5
